Kotlin's Computed Properties Are Just Methods
But don't use them to make Observables

Note: this post assumes familiarity with Java language features and conventions. RxJava familiarity is useful, but not required.
I was curious today about the relationship of Kotlin’s computed properties and methods. They do very similar things, so are they implemented similarly? (Spoiler: Yes. Yes they are.) Somehow, however, I also ended up drawing some conclusions on the semantics of reactive Observable generation. Kotlin’s computed properties can be a powerful tool for expressing your program’s intent with Observables, but you should think twice before using them for that purpose.
Observable methods vs. members
The examples of RxJava usage I’ve seen online generally use factory methods to produce Observables consumed by their subscribers. For example, using Retrofit, we’d define an API call that returns an Observable, and then later we could call this as a method on our generated service.
Observables in Retrofit example
Define a Retrofit API:
public interface GitHubService {
@GET("users/{user}/repos")
Observable<List<Repo>> listRepos(@Path("user") String user);
}
Use it while chaining Observables:
Retrofit retrofit = new Retrofit.Builder()
.baseUrl("https://api.github.com/")
.addCallAdapterFactory(RxJavaCallAdapterFactory.create())
.build();
GitHubService service = retrofit.create(GitHubService.class);
service.listRepos("octocat")
.subscribeOn(Schedulers.io())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(repos -> ...)
This is not only very easy to understand, but pretty much the only way to do this because our listRepos() method needs an argument. What if, however, we had some other method that takes no params? Could we then access an Observable as a member on some other object instead of via one of its methods?
It is in fact very possible to do something like this:
A: Observable Member Implementation
public class Stopwatch {
public final Observable<Long> currentTime = Observable.interval(1, TimeUnit.SECONDS);
}
...
// Using it:
Stopwatch stopwatch = new Stopwatch();
stopwatch.currentTime.subscribe(...);
whereas a more traditional implementation would look like this:
B: Observable Method Implementation
public class Stopwatch {
public Observable<Long> start() {
return Observable.interval(1, TimeUnit.SECONDS);
}
}
// Using it:
Stopwatch stopwatch = new Stopwatch();
stopwatch.start().subscribe(...);
There are a few things about the previous that I think are worth pointing out:
- What if, in either implementation, we had marked the
Observableasstatic? I’ll leave that for you to think about, but honestly I think that there aren’t any startling differences between static/non-staticObservables and static/non-static objects of other types. - It’s interesting to note the semantic change between using a field and using a method. I tried to highlight this by naming them differently:
currentTime(a noun) versusstart(), a verb. BothObservables are doing the same thing, but in the first case, we imply thatcurrentTimeis an observable property of aStopwatch, while in the second it is an operation that can be observed.
(Giving them the same name felt unnatural to me. I was taught that variable names should be nouns and method names should be verbs, and in fact in this old Sun Java code convention guide it is suggested thus for methods. Interestingly, however, they omit going so far as to suggest similarly giving variables noun names as well. Maybe we can think about this another time.) - In the member implementation (A), the single instance variable
currentTimeis markedfinal. I did this in order to provide functional equivalence to the second implementation (B), but are there cases in which an observable member ought to be mutable?
If theStopwatchclass had some other stateprecisionthat controlled the interval’sTimeUnit(instead of the hardcodedTimeUnit.SECONDS), the membercurrentTimewould need to be reassigned to reflect the new value, and thus could not be markedfinal.
If thecurrentTimewas no longerfinal, it would be susceptible to arbitrary reassignment. How can we protect against this? In Java, we would mark itprivate, and then provide getter access via a getter method, and then… wait. That just results in a modified version of B! Thus, if you know yourObservablemight need to change, you’re probably better off just using a method.
Kotlin computed properties are functions
Let’s get to what got me curious about in the first place. Say you have a class like Stopwatch that has some state you’d like to observe. Additionally, you aren’t restricted by the need for a parameter like the GitHub username in our very first example. Should you be using the approach A with some observable property, or approach B with methods?
Computed properties…
Kotlin has a number of features that expand what is possible in Java. For the question posed above, I am particularly interested in what I’m going to call a computed property (name taken from the equivalent feature in Swift): a field on an object that does not actually store a value, but instead uses a custom getter (and optionally, a setter) to implement normal property access. Let’s illustrate this with an example:
class Person(
var firstName: String, // Standard property with synthesized get-set accessors
var lastName: String) { // Another standard property
/**
* Our computed property! Instead of storing a value, it computes one by calling the
* getter we implement.
* This is a read-only computed property defined using `val` instead of `var`.
*/
val fullName: String
get() = "$firstName $lastName"
}
Both computed and non-computed properties are accessed the same way:
val person = Person(firstName = "Monica", lastName = "Geller")
person.firstName // "Monica"
person.lastName // "Geller"
person.fullName // "Monica Geller"
person.lastName = "Bing"
person.fullName // "Monica Bing"
Hopefully that makes sense. For another illustrative example, check out the section on computed properties in the Swift Programming Language Guide and its subsequent section on read-only computed properties here. For more on Kotlin properties, check out the appropriate Kotlin page.
…can be used like factory functions
Now, we don’t have to compute our property value from other object properties. Let’s look at a familiar example:
class Stopwatch() {
val currentTime: Observable<Long>
get() = Observable.interval(1, TimeUnit.SECONDS)
}
Yes, it’s our Stopwatch example A from before. Obviously, we can also implement the alternate implementation B in Kotlin as well:
class Stopwatch() {
// In Kotlin, a function that returns an expression does not need to be
// enclosed in braces or explicit use of the `return` keyword.
fun start(): Observable<Long> = Observable.interval(1, TimeUnit.SECONDS)
}
There is hardly any change to our Java code when it comes to actual usage, too:
val stopwatch = Stopwatch()
// Version A
stopwatch.currentTime.subscribe { ... } // Using Kotlin syntax for trailing lambdas
// Version B
stopwatch.start().subscribe { ... }
…are recalculated on each access
Notably, the read-only computed property approach does not have one of the same issues as the public final field approach in Java. Earlier we noted that if an Observable field depends on some kind of external state, the public final approach is untenable because the field would need reassignment in order to generate a modified Observable. Since a computed property uses its getter to generate a new value each time it is accessed, it is “reassigned” each time it is called.
Let’s look at an example:
class Stopwatch() {
/** Some modifiable state that the Observables depend on */
var precision = TimeUnit.SECONDS
// Version A
val currentTime: Observable<Long>
get() = Observable.interval(1, precision)
// Version B
fun start(): Observable<Long> = Observable.interval(1, precision)
}
// Usage:
val stopwatch = Stopwatch()
// Both return a subscription to `Observable.interval(1, TimeUnit.SECONDS)`
stopwatch.currentTime.subscribe { ... } // Version A
stopwatch.start().subscribe { ... } // Version B
stopwatch.precision = TimeUnit.MINUTES
// Now both return subscriptions to `Observable.interval(1, TimeUnit.MINUTES)`
stopwatch.currentTime.subscribe { ... } // Version A
stopwatch.start().subscribe { ... } // Version B
As you can see, both versions end up producing the same value. Furthermore, A is not subject to arbitrary replacement by some other Observable — it is marked as read-only (val) and cannot be reassigned.
…are in fact just functions?
Intuitively, it makes sense that a read-only computed property is just some syntactic sugar on top of methods. When you look at the property definition, the get() = ... is literally defining a custom getter method to be used for property access. What does its declaration indicate?
val currentTime: Observable<Long>
We can read that as “if you access me on/give me an object instance, I will give you an Observable<Long>.” In mathematical terminology, a relation that maps an input to an output is called a function.
Are all properties just functions inside? The conspiracy deepens.
…are indeed functions under the hood
Let’s check this out. It’s possible that there’s some subtle difference here that might contribute to our “property vs method” debate. Maybe there is some overhead in using computed properties… or will it be the other way around? This is the question that inspired this post, and we will find the answer!
In all seriousness, it’s pretty easy to find out. I propose a simple test: look at the code generated from each of the property and function implementations and see how both differ.
Example Kotlin class:
import rx.Observable
import java.util.concurrent.TimeUnit
class Stopwatch() {
/** Some modifiable state that the Observables depend on */
var precision = TimeUnit.SECONDS
// Version A
val currentTime: Observable<Long>
get() = Observable.interval(1, precision)
// Version B
fun start(): Observable<Long> = Observable.interval(1, precision)
}
The Kotlin plugin to IntelliJ provides a nifty feature that lets you look at the Java bytecode generated from any given Kotlin code. You can access this easily by tapping Cmd+Shift+A and typing in “bytecode.”
Here is the generated bytecode for our Observables in the class above using Android Studio 2.2-Preview 4 and Kotlin v1.0.2-1:
Stopwatch.kt bytecode for currentTime and start()
// access flags 0x11
// signature ()Lrx/Observable<Ljava/lang/Long;>;
// declaration: rx.Observable<java.lang.Long> getCurrentTime()
public final getCurrentTime()Lrx/Observable;
@Lorg/jetbrains/annotations/NotNull;() // invisible
L0
LINENUMBER 13 L0
LCONST_1
ALOAD 0
GETFIELD com/itsronald/twenty2020/base/Stopwatch.precision : Ljava/util/concurrent/TimeUnit;
INVOKESTATIC rx/Observable.interval (JLjava/util/concurrent/TimeUnit;)Lrx/Observable;
DUP
LDC "Observable.interval(1, precision)"
INVOKESTATIC kotlin/jvm/internal/Intrinsics.checkExpressionValueIsNotNull (Ljava/lang/Object;Ljava/lang/String;)V
ARETURN
L1
LOCALVARIABLE this Lcom/itsronald/twenty2020/base/Stopwatch; L0 L1 0
MAXSTACK = 3
MAXLOCALS = 1
// access flags 0x11
// signature ()Lrx/Observable<Ljava/lang/Long;>;
// declaration: rx.Observable<java.lang.Long> start()
public final start()Lrx/Observable;
@Lorg/jetbrains/annotations/NotNull;() // invisible
L0
LINENUMBER 16 L0
LCONST_1
ALOAD 0
GETFIELD com/itsronald/twenty2020/base/Stopwatch.precision : Ljava/util/concurrent/TimeUnit;
INVOKESTATIC rx/Observable.interval (JLjava/util/concurrent/TimeUnit;)Lrx/Observable;
DUP
LDC "Observable.interval(1, precision)"
INVOKESTATIC kotlin/jvm/internal/Intrinsics.checkExpressionValueIsNotNull (Ljava/lang/Object;Ljava/lang/String;)V
ARETURN
L1
LOCALVARIABLE this Lcom/itsronald/twenty2020/base/Stopwatch; L0 L1 0
MAXSTACK = 3
MAXLOCALS = 1
That’s a bit hard to parse, though the bytecode doesn’t look terribly different. Perhaps this will be clearer if we decompile this back into Java using the sweet new Decompile button on top here:
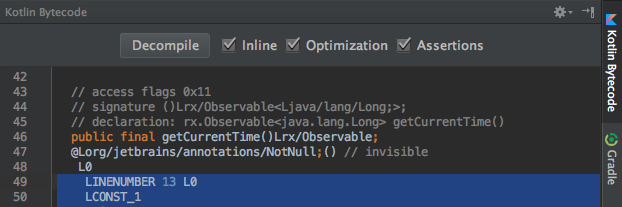
Stopwatch.decompiled.java
import java.util.concurrent.TimeUnit;
import kotlin.Metadata;
import kotlin.jvm.internal.Intrinsics;
import org.jetbrains.annotations.NotNull;
import rx.Observable;
@Metadata(
// Some generated metadata
)
public final class Stopwatch {
@NotNull
private TimeUnit precision;
@NotNull
public final TimeUnit getPrecision() {
return this.precision;
}
public final void setPrecision(@NotNull TimeUnit <set-?>) {
Intrinsics.checkParameterIsNotNull(<set-?>, "<set-?>");
this.precision = <set-?>;
}
@NotNull
public final Observable getCurrentTime() {
Observable var10000 = Observable.interval(1L, this.precision);
Intrinsics.checkExpressionValueIsNotNull(var10000, "Observable.interval(1, precision)");
return var10000;
}
@NotNull
public final Observable start() {
Observable var10000 = Observable.interval(1L, this.precision);
Intrinsics.checkExpressionValueIsNotNull(var10000, "Observable.interval(1, precision)");
return var10000;
}
public Stopwatch() {
this.precision = TimeUnit.SECONDS;
}
}
Surprise, surprise. currentTime and start(), and their generated counterparts getCurrentTime() and start(), have exactly equal implementations. They are the same except for their names! While we used a bit of a trivial example, I also went ahead and tried this with some much more complex Observables and ended up with the same result.
Read-only computed properties are just functions under the hood.
So… which way do I use?
Let’s do a quick comparison.
Java
In pure Java, you are almost certainly better off using the method implementation of Observable generation. There is a reason that you fairly exclusively see this practice in examples, and it all comes down to safe usage patterns through encapsulation.
As a reminder, exposing an Observable field on an object:
- Allows unsafe assignment unless marked
final - Make it unable to adapt to changes to its enclosing object’s other fields if marked
final - Can’t take or use arguments.
Methods, on the other hand:
- Are immutable
- Generate their return values when called and thus react to changes in their enclosing objects’ other fields
- Can have arguments.
Kotlin
Kotlin’s property syntax allows a very different style of programming than when only using Java. As we’ve found, using a computed property gives us the power of a getter method with the access pattern of an object field.
With regard to data generation, computed properties:
- Do not allow unsafe reassignment
- Generate their return values when called and thus react to changes in their enclosing objects’ other fields
- Still can’t take arguments.
I submit that perhaps, then, computed properties are a solid alternative to methods for many data types. Certainly they have the capacity to clarify the intent of our programs. If your computed property is just a thin API that provides access to an in-memory field, you should definitely be using it instead of a method.
However…
Observables aren’t simple data types
Most Observable objects are complex and expensive to create. If your computed property instantiates a new Observable every time it’s accessed, using a method better signals that we are building a new object that shouldn’t be used carelessly.
Some Observables have side effects
If the Observable you expose as a property implements doOnNext(), you have now introduced unknown side effects in what is supposed to be a simple data access.
Or, if you have assigned a Scheduler to the Observable, you may have just created a new thread, unbeknownst to the caller! When using a method, there is an implicit understanding that the code body might just do more than accessing a value.
Observables are inherently asynchronous
Asynchronous interactions are notoriously difficult to reason about. The Observable class is meant to ease some of the cognitive load on the programmer, but it still remains that they represent some kind of potential asynchronous value. This leads back to the first point that Observables aren’t simple and that methods better reflect their complexity. In fact, many common Observables represent long running operations, and actions an object takes are better represented as methods.
Note: A good resource I found on this subject is the MSDN guide on “Choosing Between Properties and Methods”.
TL;DR: Kotlin computed properties are just methods, but that doesn’t mean you should be using them to expose your object’s Observable API.
Now it’s time for me to start migrating my computed Observables to straight methods… :-P

Share this post
Twitter
Facebook
Reddit
LinkedIn
Email